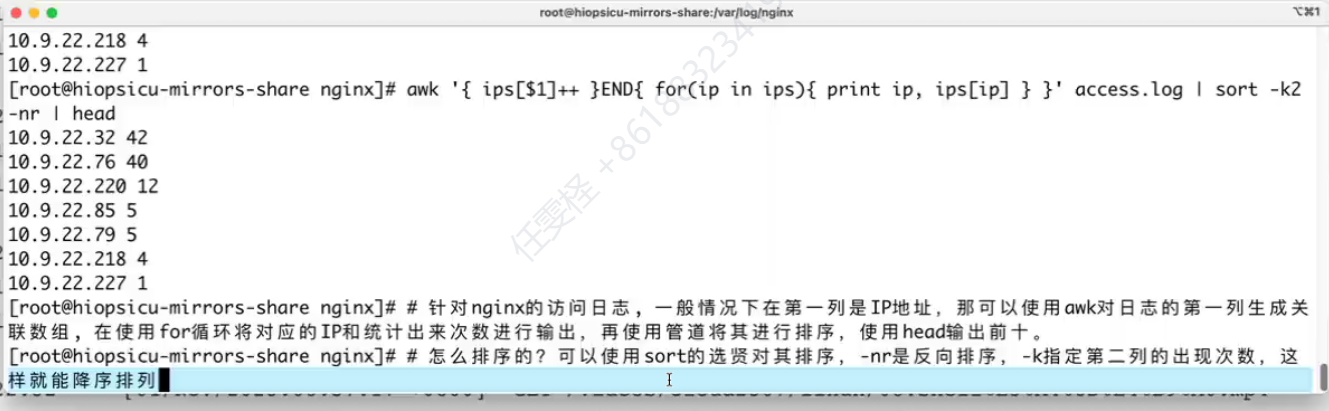
--------------------------------------------------
用户删除了仍在使用的文件,文件删除了但是文件句柄仍然保留,df命令统计文件句柄,du命令不会在文件系统目录中统计这些文件。
解决方法:使用lsof | grep deleted 命令查找到带有deleted标识符的进程PID,然后kill -1 PID 重启它,就恢复正常
命令:lsof | grep deleted | grep -v PID | awk '{ pid[$2]++ }END{ for(p in pid){ print "kill -1",p}}' | bash -
首先客户端根据浏览器中提供的域名进行DNS解析获取到服务器的IP地址,再根据url中提供的port确定访问的端口号,至此客户端操作系统会与服务器操作系统建立TCP三次握手并形成网络通路,至此浏览器封装请求体,将请求体所建立的TCP通路传输到服务器中,服务器将请求体解开,根据提供的请求行的url以及请求头中的头部信息以及请求体中的验证信息将请求的资源封装成响应体,再增加响应头、状态行、沿原来的通路传给客户端。
意义:TCP三次握手给HTTP信息传输,提供了稳定的底层支持,符合OSI七层参考模型的:下层服务于上层的理念。
初始化请求体包含请求行(包含了Method、URL、Version)、请求头(包含了由服务器确定的请求头)、请求体(包含了用户信息、令牌等)
初始化响应体包含响应行(包含了http状态码、Version)、响应头(返回请求头对应的响应头)、响应体(包含了html、css、JavaScript、媒体文件等)
1、用户在浏览器输入url
2、浏览器根据输入的url地址确定服务器的IP地址
3、浏览器开始构建请求体
4、利用http三次握手将请求体传输到服务器
5、服务器接收并识别请求体中的用户信息并进行身份甄别
6、根据URI判断是否包含对应的资源
7、如果不包含:返回带有错误状态码的响应体。如果包含:封装好对应的初始响应体并按照接收路径向浏览器返回响应。
1、打开浏览器输入www.baidu.com后按回车
2、浏览器根据输入的url地址确定服务器的IP地址(使用了DNS协议)
3、浏览器开始建立三次握手通道然后构建请求体(请求行:Method URL Version、请求头:由服务器确定、请求体:包含了用户信息,令牌等信息)
4、电脑通过三次握手将请求体传输到服务器
5、服务器接收并识别请求体中的用户信息进行身份甄别
6、根据URI判断是否包含对应的资源
7、如果不包含:返回带有错误状态码的响应体。如果包含:封装好对应的初始响应体并按照接收路径向浏览器返回响应。
8、用户看到网页界面
--------------------------------------------------
400:请求报文中存在语法错误(URL写错了)-----客户端检查URL
401:认证信息不存在于请求头中(未认证)-----给用户返回让用户先登录
403:请求资源未找到or对访问的URI地址没权限-----让用户提升权限
404:请求资源未找到-----给用户返回请求资源未找到
413:请求体中的数据过大,服务端无法处理这么大的请求体-----调整吞包的上限,一般设置为256M
429:客户端短时间内发送了太多请求,被限制访问了-----减少发送请求的次数
431:请求体重的header头字段太大了,服务端无法处理这么大的头部信息-----调大请求头处理的上限
500:服务端中的代码存在bug-----让研发参与(修bug)
502:多指代理服务器的配置有问题-----检查nginx配置是否有问题、检查代理服务器和负载均衡器时候宕机,登陆上去启动它
504:多指代理得上游服务器错误,通常是代码执行超时、代码发生了死循环-----找到研发,让研发支持解决问题
503:服务器处于超负载or维护状态-----临时加配置
--------------------------------------------------
浏览器构造请求体向服务端发送请求, 服务端接收到请求后将被访问域名的证书返回给浏览器, 此时浏览器对证书进行验证, 如果验证为不合法则浏览器警告用户“不安全”, 如果验证正常则生成一个随机数, 并使用证书对该随机数进行加密, 并将加密后的随机数传给服务端, 此时服务端通过私钥解密随机数, 再使用随机数对要返回的响应体进行加密传送给浏览器, 浏览器在通过对应的随机数进行解密, 以此建立的加密通信
--------------------------------------------------
使用两个for循环第一个循环中读取所有负载均衡的配置文件,第二个要读取到文件里的IP,针对读取到的ip进行探测,探测方式采用curl方式,探测成功的话不管,探测不成功的话就把ip下掉设置为down,然后重启nginx生效。
--------------------------------------------------
我们这边的调优我没做过,但是我看到我们公司的nginx是做了CPU的亲和性的,也做了worker进程的优先级
--------------------------------------------------
我们公司是全栈https,用得是同一个证书,原因是为了cdn服务器在回源或溯源的时候不会因为证书报出443连接错误。
因为是内网,所以低不到那里去。
--------------------------------------------------
主库开启二进制日志,通过mysqldumpthread进程与从库的IO线程进行数据共享,从库IO线程将读取到的数据写入到本地中继日志中,从库的SQL线程将中继日志中的数据回放到从库中,以此完成数据同步。
--------------------------------------------------